Character Encoding - BBj
Description
When the BBx language was originally defined, the distinction between characters and bytes could often be ignored. The underlying character set was assumed to be ASCII or extended ASCII (Windows-1252, ISO 8859-1, and later MacRoman). BBx string functions like CHR() and ASC() implicitly assume that a character is a single byte within the range 0 to 255, and substring references treat bytes and characters as interchangeable concepts.
Over time, these legacy single-byte character sets were superseded by multi-byte character sets, most of which were based on the evolving Unicode standard. Internally, Java strings are UTF-16, while the Web is almost entirely UTF-8. In Java 17 and earlier, Java defined the default character encoding on startup based on "the locale and charset of the underlying operating system." With the notable exception of Microsoft Windows, most platforms now define the default character encoding to be UTF-8. Starting in Java 18, Java standardized its default character encoding to be UTF-8 on all platforms, including Microsoft Windows.
Because some applications depend on the assumption that they're running in Microsoft Windows with the Windows-1252 character set, a compatibility flag is available to revert to the legacy character encoding.
This sample program shows how character encoding works in different environments:
|
If we run that program in Microsoft Windows using Java 17, we see the legacy Windows-1252 single-byte character set:
Windows 11 10.0
Java 17.0.12
Server character set: windows-1252
Client character set: windows-1252
Euro$: �
len(Euro$): 1
hta(Euro$): 80
Euro!.length(): 1
Euro!.codePointAt(0): 8364
If we run that program in Microsoft Windows using Java 21, we see UTF-8, the new Java default character set:
Windows 11 10.0
Java 21.0.4
Server character set: UTF-8
Client character set: UTF-8
Euro$: �
len(Euro$): 3
hta(Euro$): E282AC
Euro!.length(): 1
Euro!.codePointAt(0): 8364
This highlights the byte-oriented nature of the BBx string functions: The Euro$ string variable contains a single character, but UTF-8 encodes that single character in three bytes. The BBx LEN() function reports the length of the string in bytes. The BBjString API can be used to examine that string in terms of Unicode characters, as opposed to raw bytes: BBjString::length reports that the string contains one Unicode character, and BBjString::codePointAt reports that the first character of that string is Unicode 8364, the Euro symbol (�).
If the application depends on the assumption that the underlying character set is Windows-1252, we can add a new compatibility setting, -Dfile.encoding=COMPAT, to all BBj Java Args in Enterprise Manager by going to  Java Settings and clicking
Java Settings and clicking  .
.
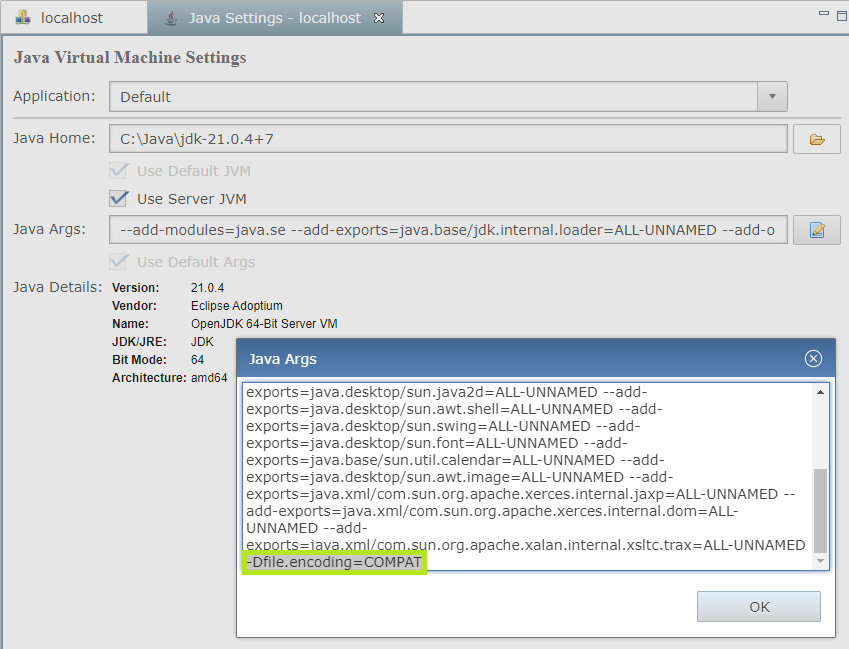
After adding that compatibility setting to all BBj Java Args values and restarting BBjServices, the sample program reverts to the original Java 17 behavior:
Windows 11 10.0
Java 21.0.4
Server character set: windows-1252
Client character set: windows-1252
Euro$: �
len(Euro$): 1
hta(Euro$): 80
Euro!.length(): 1
Euro!.codePointAt(0): 8364
See Also
Character Sets and Character Encoding
For more information about the Unicode standard, see unicode.org