Document Indices
Access to this feature requires an active Software Asset Management (SAM) subscription. See Benefits of ‘Software Asset Management' Feature Line.
In BBj 16.0 and higher, Document Indices provide BBj developers with a
powerful document indexing solution powered by the Lucene
search engine. Lucene is the accepted standard when it comes to incorporating
full-text searching capabilities into Java-based applications. Using the
document indices built into BBj, developers have access to the lighting-fast
searching capabilities provided by Lucene’s rich, flexible query language.
What is a Document Index?
Document indices in BBj consist of a named configuration that describes the following:
-
Location of the Lucene index directory
-
List of one or more directories to monitor for new documents to index
-
List of file extensions to be indexed
-
Various Lucene configuration options including advanced language and tokenization customization
The document index watches the list of monitored directories for any new or removed documents whose filename extensions match one of those in the list and indices them (or removes them from the index). This makes the document available for full-text searching.
Creating a Document Index
Two options exist for creating document indices: Admin API and the Enterprise Manager. For details on using the Admin API, see Interface BBjAdminBase.createDocumentIndex(). Using the Enterprise Manager is the easiest way to create a new document index and get it up and running fast. The Document Index Wizard walks the developer/administrator through three steps to setup a document index.
Step 1 - Specify a unique name for the document index.
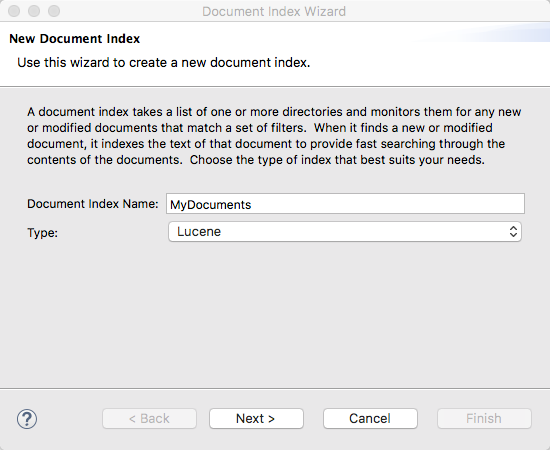
Step 2 - Specify the location for the Lucene index directory and any language-specific setting.
In addition to this vital piece of information, it may be necessary to change some of the default options. Note that these are not necessary for most installations. RAM Buffer Size MB, Allow Leading Wildcards, and Lucene Analyzer Class are advanced Lucene configuration options that are beyond the scope of this document. See the Lucene Documentation for more details.
Stopwords Language Code
The Stopwords Language Code is an important setting for those databases containing non-English data. It is up to the individual developer/administrator to determine how to best handle this setting. A stopword is a language word that has no significant meaning in a keyword based search system (e.g. Google). Lucene has a number of languages configured with a set of such words. These words are simply ignored while analyzing/tokenizing text. English is the default language, however, if the contents of the database are in a different language, searches may be more effective if the language is set to the language of the data. Some examples of English stopwords are a, an, it, the, in, for, etc. Note that this setting cannot be changed later without recreating the document index.
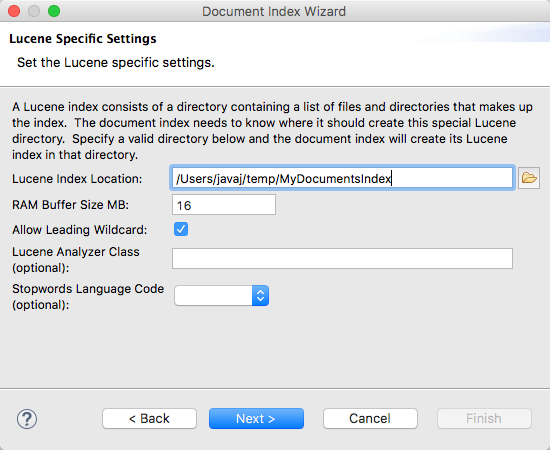
Step 3 - Include the list of directories to monitor and a list of acceptable file extensions.
NOTE:
After creating the document index, it may a few moments before all of the documents are indexed and available for searching.
Querying a Document Index
Two methods exist for querying document indices. The most common and useful from an application standpoint is the use of the Admin API. However, the Enterprise Manager provides a nice, simple interface for performing ad-hoc queries, building a query using a helpful query builder, and testing potential queries to ensure they return the expected data.
Search Using the Enterprise Manager
To open the search editor in the Enterprise Manager, select the document index from the list of available document indices and click the magnifier icon on the toolbar.
The search editor provides a textbox to enter a Lucene-compatible search query. Hit Enter to perform the search. For assistance in building a search query, select the edit button to the right of the search textbox to open a query builder.
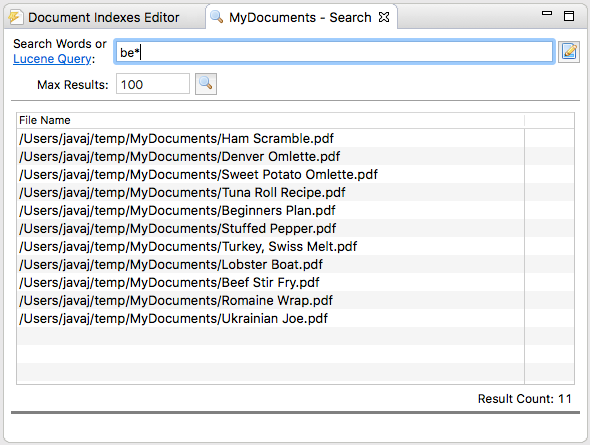
Example 1
Example 1 shows the results from querying some documents containing recipes. The search query is “be*” which means all those documents that contain a word that begins with “be”. This would include those that referenced “beef”, “beans”, “beets”, etc. Queries are case-insensitive by default.
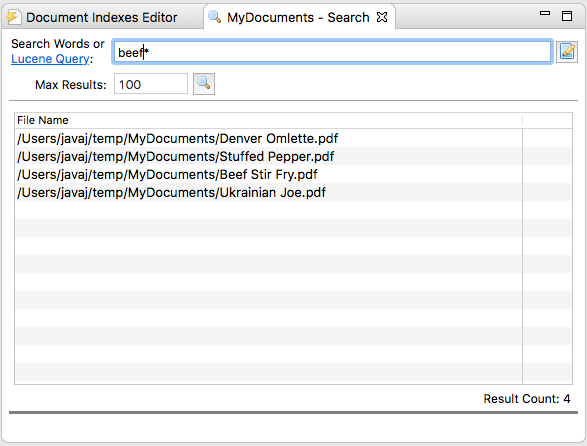
Example 2
Example 2 makes the filter more specific. Now, only those recipes that have a word beginning with “beef” will match the query. This would include “beef”, “beefy”, etc.
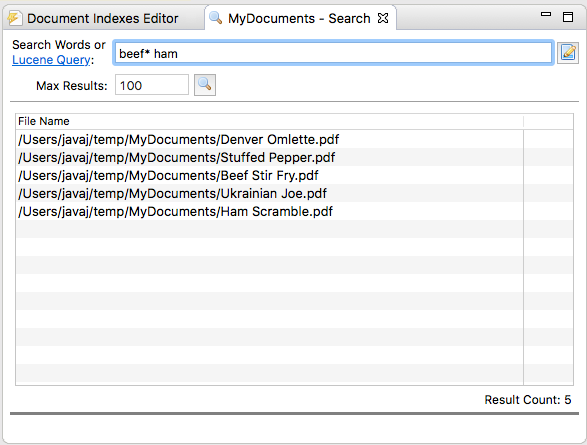
Example 3
Example 3 adds a second term to the query. The default operator for terms is OR so the following query would return those recipes with a word starting with “beef” and containing the exact word “ham."
There are numerous possibilities for providing criteria to gain more control over the results. While the query builder can help with some of the more advanced options, be sure to consult the Lucene Query Syntax documentation for complete details on all the options available in the Lucene Query Language.
Search Using the Admin API
With a configured document index, developers write BBj code that utilizes the Admin API to manage and query the document index to provide powerful searching capabilities to their applications. The API is very simple. The following example performs two queries on the document index. The first query performs a search for all documents containing the word “beef” OR “ham." Note that matches are performed on whole words unless wildcard characters are included. In the second example, a wildcard is used to find all documents with “chick*” (meaning a word starts with “chick”) OR “fish." We won’t go into details on the query language, but know that it is very robust and very powerful including the ability to perform partial matching, fuzzy matching, ranges, equality, etc. For complete details see Lucene Query Syntax for a complete explanation and examples.
|
REM Connect to the Admin API |
See Also
Full Text Indexing and Searching