Using FULLTEXT Files/Indices for Searching
Once
FULLTEXT files or indices are created, perform searches in any of these
three ways:
- Use BBx READ RECORD calls
- Execute one of the special SQL system stored procedures (SPROCs)
- Use the Search user interface in the 'Browser' or 'Eclipse' Enterprise Manager
Lucene Query Language
With BBj using Lucene for its FULLTEXT file/index implementation, the full Lucene query language is available to the user for performing simple or complex searches. Searches can be as simple as one or more case-insensitive words to include in the results to something arbitrarily complex including fuzzy matching, exclusions, and more. For more information on the query language, refer to these online Lucene resources:
Search Using BBx READ RECORD
BBj programs can access FULLTEXT files using direct file access calls or SQL (discussed below). When using READ RECORD, the result is similar to accessing any other type of BBj data file, however, there are some differences.
First, instead of positioning the file pointer at a particular location in the file, the READ RECORD call tells the file channel to temporarily limit the viewable results to those records that match the search query. The order of these records will not be in a known order, but rather, in order of relevance to matching the query. The algorithm for determining relevance is part of the Lucene library and cannot be configured by BASIS or the user. Relevance is similar to how a search engine such as Google returns a list of matching results with the "best" matches at the top of the list (according to what Google thinks is a "best" match).
Another difference is in the KNUM and KEY parameters to the READ RECORD call. There are only two valid key numbers on a FULLTEXT file: 0 and 1:
-
KNUM=0: Indicates that the program would like the single record that matches the primary key as specified in the KEY= parameter.
-
KNUM=1: Indicates that the KEY= parameter contains a Lucene format query to generate a limited list of records that matches the query.
For example, assume we have a FULLTEXT file created with the template defined in the code below where the key field was CUST_NUM as shown here:
chan = unt
OPEN (chan) "/path/to/my/file/CUSTOMER.text"
DIM rec$:"CUST_NUM:C(6),FIRST_NAME:C(30),LAST_NAME:C(30)"
REM Read record with CUST_NUM = 000001
READ RECORD (chan, KNUM=0, KEY="000001") rec$
REM Read first matching record for a Lucene
REM query returning all records with a last
REM name of Smith
READ RECORD (chan, KNUM=1, KEY="smith") rec$
REM Read first matching record for a Lucene
REM query returning all records with a last
REM name that STARTS with Smith (note asterisk)
READ RECORD (chan, KNUM=1, KEY="smith*") rec$
Searching Using SQL System SPROCs
IMPORTANT NOTE: The Lucene search engine used by the BBj FULLTEXT index feature includes a setting used to limit the maximum number of search results by any operation using Lucene. This limit is used to reduce the resources used by the Lucene system, and defaults to 1,000. This limit overrides the limit provided in the search query. If result sets larger than 1,000 are needed, see the "Max Search Results" setting on the BBjServices: Settings page in the Enterprise Manager.
BBJ_SEARCH_TABLE
The BBJ_SEARCH_TABLE SPROC returns a result set that looks the same as the result of a SELECT * statement from the table and is suitable for use in nested SELECT statements and joining with other tables.BBJ_SEARCH_TABLE takes 3 parameters:
-
Table Name: Single table name to search
-
Query: Lucene format search query
-
Maximum Results: Maximum number of results to return where 0 indicates no limit
Example 1
The following wildcard example finds all customers who have a FIRST_NAME or LAST_NAME that starts with “Ch” in the ChileCompany demo database:
SELECT * FROM (CALL bbj_search_table('CUSTOMER', 'Ch*', 0))
While the example above is quite simple, Lucene provides a very robust query language. See Apache Lucene - Query Parser Syntax for complete information.
Example 2
This example uses more complexity. Using the ChileCompany demo database, this query returns all orders with a customer with a LAST_NAME ending with “son”. Specifying the column name in the Lucene query allows the query to examine only part of the values in the index:
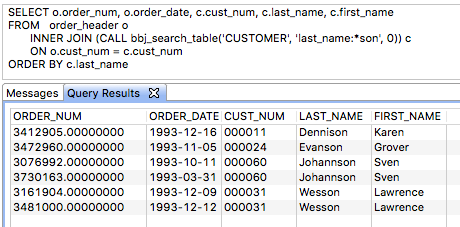
SQL has some specific expected behavior when using WHERE clauses to limit search results in queries. As a result, it is necessary to handle FULLTEXT index searching in a special way apart from a simple WHERE clause. To accomplish this, BBj has two special system SPROCs available: BBJ_INDEX and BBJ_SEARCH.
BBJ_INDEX
The BBJ_INDEX SPROC returns a list of the records from the FULLTEXT file attached to a particular table, that match the specified Lucene query. For example, using the Chile Company demo database that comes with BBj 15.0 and higher (FULLTEXT index on the DESCRIPTION column in the ITEM table), the following images shows a query that returns a list of all the items in the ITEM table’s FULLTEXT index that have the word "chile" and/or a word ending with "shirt" (t-shirt, shirt, TShirt, dress-shirt, etc.):
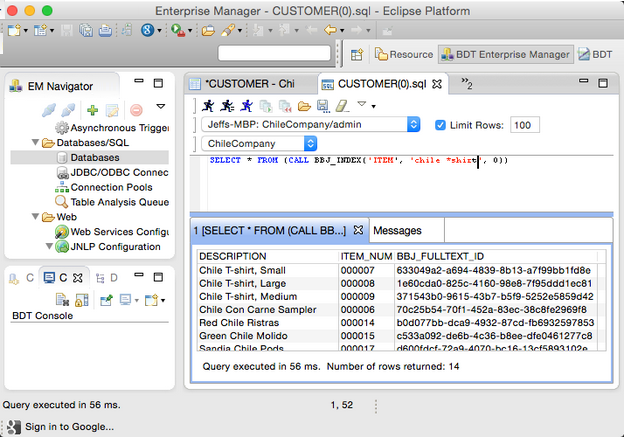
The SQL performs a SELECT from the result of a CALL to execute the BBJ_INDEX SPROC. This is important as we will see in the next example that performs a join with the table to return all the row data matching our search. Note the three columns in the result. The DESCRIPTION column was the column used to define the FULLTEXT index and the information our search query examines to determine the results. However, the Lucene FULLTEXT file contains the synchronized table’s primary key as well as a unique record ID for the index. The unique record ID can be ignored for the most part. The result includes a column for each primary key segment with its value. The primary key value comes in very handy as shown in this example:
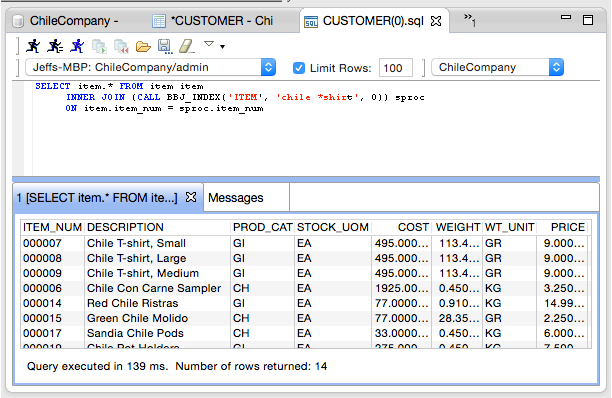
By joining the results of the SPROC call with the actual table, we are able to get all the columns from the table for each record that matches one of the records from the search results. Also note that the order of the results is by relevance and all the records have "chile" or "*shirt" somewhere in the description. However, the first three in the result have "chile" AND "shirt" which means they are more "relevant" than those with only "chile".
BBJ_SEARCH
The BBJ_SEARCH SPROC is similar to the BBJ_INDEX SPROC, but it allows the user to search one or more tables with FULLTEXT indices in a database at the same time (even the entire database). The results are a bit different than the BBJ_INDEX SPROC, so there are additional steps that need to occur to process the results beyond a quick overview of the matching data.
The following screen shows an example of the results a call to BBJ_SEARCH returned:
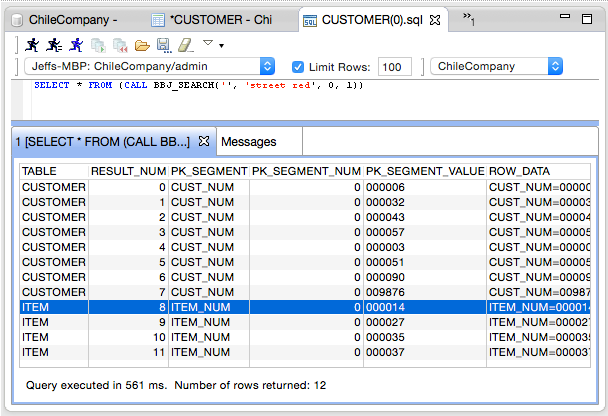
The CALL to BBJ_SEARCH does the following:
- Parameter 1 is an empty string that means "all tables with FULLTEXT indices." Instead, the user can specify a single table, list of comma separated tables, or use wildcards that follow the SQL LIKE syntax such as 'CUS%'.
- Parameter 2 is the Lucene query that says all records with "street" and/or "red" somewhere in one of their indexed fields.
- Parameter 3 is the maximum number of results (0 indicates all results).
- Parameter 4 is 1 to return a row data preview or 0 if no preview is needed (faster).
The results shows the outcome of executing a call to BBJ_SEARCH. Interpret the result columns as follows:
|
TABLE |
The table where the match was found. |
|
RESULT_NUM |
The result number. The matches are returned grouped by table and the matches within the table grouping are in order of relevance for that table. |
|
PK_SEGMENT |
The name of the primary key segment that the PK_SEGMENT_VALUE comes from. There can potentially be multiple rows to point to a single record if the primary key has more than one segment, because each row describes one segment of the primary key and its value. |
|
PK_SEGMENT_NUM |
The primary key segment number this row describes. For single segment primary keys, there will only be one row for each matching record. For multiple segment primary keys, there will be one row for each segment of the primary key. |
|
PK_SEGMENT_VALUE |
Primary key segment value for the matching row. |
|
ROW_DATA |
If parameter 4 in the SPROC CALL is 1, then this will contain a list of all the record field values as a pipe separated name=value pair. This is designed for quick review of the data. The TABLE, PK_SEGMENT, PK_SEGMENT_NUM, and PK_SEGMENT_VALUE results should be used to locate the matching record in the original table if needed. |
This SPROC call is not conducive to joins with anything else, which means that unlike the BBJ_INDEX SPROC, processing of these results must be done with application logic.
BBJ_SEARCH_RELATED
NOTE: Available only for Enhanced and Barista format databases because it relies on the presence of foreign key definitions found only in these two types of BBj databases.
The BBJ_SEARCH_RELATED stored procedure is a powerful tool to search the FULLTEXT indexes on multiple related tables of data for information, all in a single call. It is important to note that it only searches the FULLTEXT indexes, not standard indexes or other column values not included in the FULLTEXT index for a table. The result set contains the results of joining the primary table with the related tables on any associated foreign keys, much in the same way an INNER JOIN works when performing a SELECT on multiple tables. However, this SPROC performs all the joining automatically without any need for specifying join criteria.
Parameters
|
PRIMARY_TABLE |
Primary table to search. For example, in a master-detail relationship, this would be the "master" table. |
|
RELATED_TABLES |
Secondary table(s) related to the primary table. For example, in a master-detail relationship, this/these would be the "detail" table(s). Each related table should be separated by a comma. For example: TABLE1,TABLE2,TABLE3 |
|
SELECT_ITEMS |
SELECT items to be included from the primary and related table(s). A single asterisk (*) will include all columns from all tables. To include only some columns from some tables, include a list of comma-separated columns in the format TABLE.COLUMN. If there is no ambiguity in column names (i.e. column name only appears in one table), feel free to leave off the explicit table reference. This follows the same format as a typical SELECT statement’s SELECT list would follow. |
|
QUERIES |
List of pipe-separated (|) Lucene-format search queries to be executed on each table included. The first item references the primary table, and subsequent items reference the related tables. A query must be included for each referenced table. See the example below for details. |
|
MAX_RESULTS |
Maximum number of results to return or 0 for no limit. |
Example 1
Perform a JOIN between the CRM_CUSTMAST and ARC_SHIPVIACODE tables on the foreign key definition. The result will include records where the CRM_CUSTMAST table has the word “Western” at the beginning of the value in one of the FULLTEXT indexed columns in the CRM_CUSTMAST table OR the word “Ground” anywhere in the value of a FULLTEXT indexed column in the ARC_SHIPVIACODE table:
CALL BBJ_SEARCH_RELATED
('CRM_CUSTMAST', 'ARC_SHIPVIACODE', '*', 'Western*|*Ground*',
0)
Example 2
Perform a JOIN between the CRM_CUSTMAST and ARC_SHIPVIACODE tables on the foreign key definition. The result will include records where the CRM_CUSTMAST table has the word “Western” at the beginning of the CUSTOMER_NAME column in the FULLTEXT index on the CRM_CUSTMAST table OR the word “FedEx” anywhere in the value of the DESCRIPTION column in the FULLTEXT index on the ARC_SHIPVIACODE table. The result will only contain the CUSTOMER_NAME and DESCRIPTION column values:
CALL BBJ_SEARCH_RELATED
('CRM_CUSTMAST',
'ARC_SHIPVIACODE',
'CRM_CUSTMAST.CUSTOMER_NAME, ARC_SHIPVIACODE.DESCRIPTION',
'CUSTOMER_NAME:Western*|*DESCRIPTION:FedEx*', 0)
Enterprise Manager Search Viewer
Using the BBJ_SEARCH SPROC is more complex than the simplicity of the BBJ_INDEX SPROC. However, for those who do not wish to write application logic to process the results of the BBJ_SEARCH SPROC, the Browser and Eclipse Enterprise Managers provide this powerful Search Viewer:
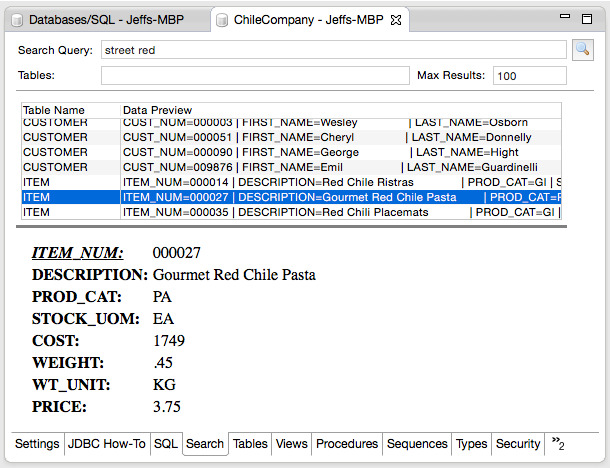
Execute a search on a database from the EM
- Double-click on the 'Databases' node.
- Double-click on the database of interest.
- Select the ‘Search’ tab.
- Enter the search query, any table names, and maximum results.
- Execute the search by clicking the magnifier or pressing Enter.
- Click on a search result to see the record details.
This simple, but powerful search viewer provides a great interface for testing Lucene searches and quickly viewing the results of searches on one or more tables at one time. The grid shows the table and quick data preview so you can quickly scroll through and see all the matches to your query. Selecting an item from the grid displays the complete record in the details section below the results grid.
See Also
Full Text Indexing and Searching