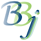
SQL FULLTEXT Indices
Access to this feature requires an active Software Asset Management (SAM) subscription. See Benefits of ‘Software Asset Management' Feature Line.
BBj also makes Luceneavailable
in the SQL engine to dramatically improve the searching capabilities on
tables in a database. Note that only one FULLTEXT index is allowed per
table but you may include as many columns as necessary in each index.
Keep in mind that the more columns included, the slower it will be to
write records to the index, and the larger the index will become. Only
include those columns that would be useful in FULLTEXT searches.
Create a FULLTEXT Index
Create a FULLTEXT index using SQL or with the Enterprise Manager table editor (this process may take a while depending on the number of records in the table).
SQL Statement
CREATE FULLTEXT INDEX ON
customer (first_name, last_name, bill_addr1, bill_addr2)
Enterprise Manager Table Editor
The Enterprise Manager (EM) table editor provides a convenient user interface for managing FULLTEXT indices on tables like the one shown below:
Important Note Regarding Index Creation
In BBj 18.00 and higher, FULLTEXT index creation occurs in a background process. This means that creation of a FULLTEXT index using the Enterprise Manager, Admin API, or SQL will return immediately while building of the index occurs in the background. Users can continue accessing the data file during the creation process, however, FULLTEXT query features are not available until completion.
Administrators can monitor the building of FULLTEXT indexes using the Index Builders panel in the Enterprise Manager under the Databases item in the navigator:
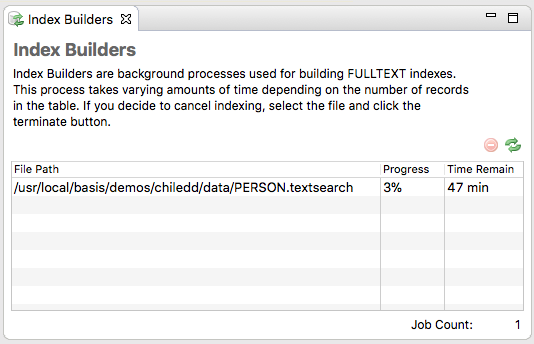
The Index Builders panel displays a list of all currently running FULLTEXT index building jobs, the progress as a percentage, and an estimated time remaining. Click the refresh button to refresh the display.
To cancel building of an index, simply select the build job, and click the terminate button.
Use Full Text Index
In BBj 16.0 and higher, place a check in the box to create a FULLTEXT index on the table. The index will be created when saving the table definition. Unchecking this box and saving the table definition removes the index.
Lucene Analyzer Class
In BBj 16.0 and higher, from the Lucene Javadocs, "An Analyzer builds TokenStreams, which analyze text. It thus represents a policy for extracting index terms from text." This advanced setting should rarely be changed from the default. However, if your requirements involve the use of an alternate analyzer, specify the class implementation here. Be sure to add any required JARs to your BBj classpath under BBjServices->Java Settings->Classpath before making any changes.
Stopwords Language Code
In BBj 16.0 and higher, a stopword is a language word that has no significant meaning in a keyword based search system (e.g. Google). Lucene has a number of languages configured with a set of such words. These words are simply ignored while analyzing/tokenizing text. Prior to 17.02, English was the default language while 17.02+ uses a default of no language stopwords. If the contents of the database are in a different language, searches may be more effective if the language is set to the language of the data. Note that this setting cannot be changed later without dropping and recreating the index.
Important Notes Regarding Stopwords
Why does the default stopwords configuration use no language and thus, no stopwords? This is an extremely important decision to make when creating a FULLTEXT index. Stopwords are used to make the index more compact. This is due to the fact that when indexing text content, when a stopword is encountered, it is left out of the index. While the data is still written to the record, the stopword will not be found when searching the index so seemingly incorrect results can occur. For example, if the following sentence was present in a FULLTEXT indexed field using English as the stopwords language, there are some important things to understand:
“The quick brown fox jumped over a lazy dog.”
The entire value is stored in the record as expected. However, during indexing, the only words indexed would be quick, brown, fox, jumped, over, lazy, and dog. “The” and “a” would not be indexed because they are stopwords and generally don’t add anything meaningful when searching for matching data. So, a search for “quick” or “brown” would locate this record as a match, but searching for “the” or “a” would find no matches.
This is generally not an issue if the indexed data consists of whole language sentences. However, if the indexed data also includes product identifiers, abbreviations, or other values that may look like a stopword but in fact need to be searchable, then the best option is to use no stopwords language so that all words are indexed and thus, searchable. If in doubt, the safest option is to choose no stopwords to ensure accurate results in every case.
Create a FULLTEXT Index
- Log into the EM.
- Double-click on the Databases node.
- Double-click on the desired database.
- Click on the ‘Tables’ tab and double-click on the table on which to add the FULLTEXT index.
- Select the ‘FullText Index’ tab.
- Mark the ‘Use Full Text Index’ checkbox.
- Select the columns to include in the index.
- Save the changes using Ctrl/Cmd+S or File > Save.
Column Selection
In BBj 16.0 and higher, since only one FULLTEXT index may be present on a table, it is important to select any columns that should be available for FULLTEXT searches. Keep in mind that the more columns present in the index, the longer write operations on the data file will take (this is is milliseconds so it may not be an issue). Note that if the primary key column or columns are not selected, they will be added to the index automatically. This is necessary for lookup operations during queries using the results of a FULLTEXT search operation.
Lucene Index Binding
In BBj 16.0 and higher, both the SQL and EM examples create a FULLTEXT file that is tied to the CUSTOMER table, similar to a trigger. This FULLTEXT file consists of a <filename>.sync file which ties the file to the Lucene index, and a Lucene index which is a directory named <filename>.textsearch. The creation process creates these files in the same directory as the table’s data file. When changes are made to the table data file, those changes are also made in the Lucene index so they stay in sync. Note that changes made using WRITE/WRITE RECORD/REMOVE also update the FULLTEXT index appropriately. This way the FULLTEXT index remains in sync regardless of the method used to update the data file.
See Also
Full Text Indexing and Searching
FULLTEXT Verb - Create FULLTEXT File
Using FULLTEXT Files/Indices for Searching